
Share post
Audience: technical
Remember that in my previous post (geared toward non-technical audiences) I took a look mostly at the new platform Bluesky. While I dived partially into some of the cool tech that makes Bluesky unique, I did not really go much more than an inch below the surface. In this post I want to come back to this topic and look at specifically their protocol they developed called Authenticated Transfer Protocol, or ATProto for short.
I generally like to have a plan of attack, so based on some of the reading I did from before on their documentation, I plan on addressing it thusly:
- Fundamentals within the protocol
- The underlying mechanics within the protocol
- Exploring the SDKs Bluesky built for ATProto.
- We will focus on the fully-featured Typescript SDK

I also believe at this point it is important to note that I will be speaking technically, and while I will try to keep things as simple as possible, this is inherently a tech-oriented post. To make this post shorter than a book, I will assume that you grasp some basics around web services like APIs, HTTP and websockets and some common tech therein like JSON and JSONSchema.
If you agree with this plan and want to keep going on this journey with me, let’s get into it!
Starting from the top
Bluesky’s vision
At this point I like to remind myself what it is that Bluesky was trying to achieve with this new protocol. The reason it is important to have their vision in mind, is because everything we dig into will have that ultimate purpose as the reasoning behind decisions taken, and implementations coded.
Put simply, Bluesky is attempting to build decentralized social media. Whoah there’s that fancy word decentralized again. So once again I look at the two reference photos from my earlier post with some context added.
Centralized social media platform where one entity controls everything:
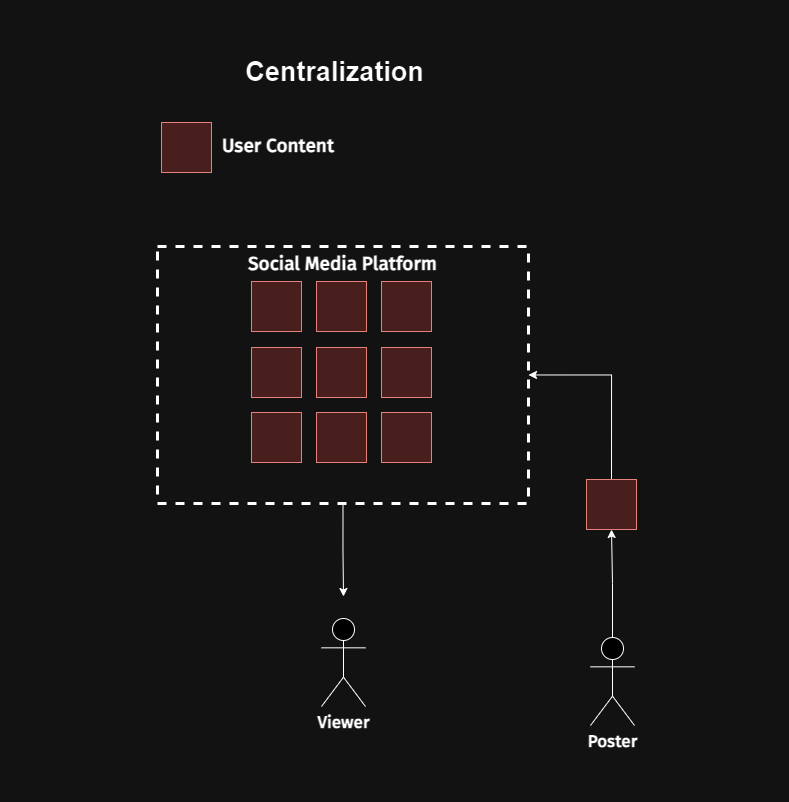
Decentralized social media platform where no single entity controls everything.
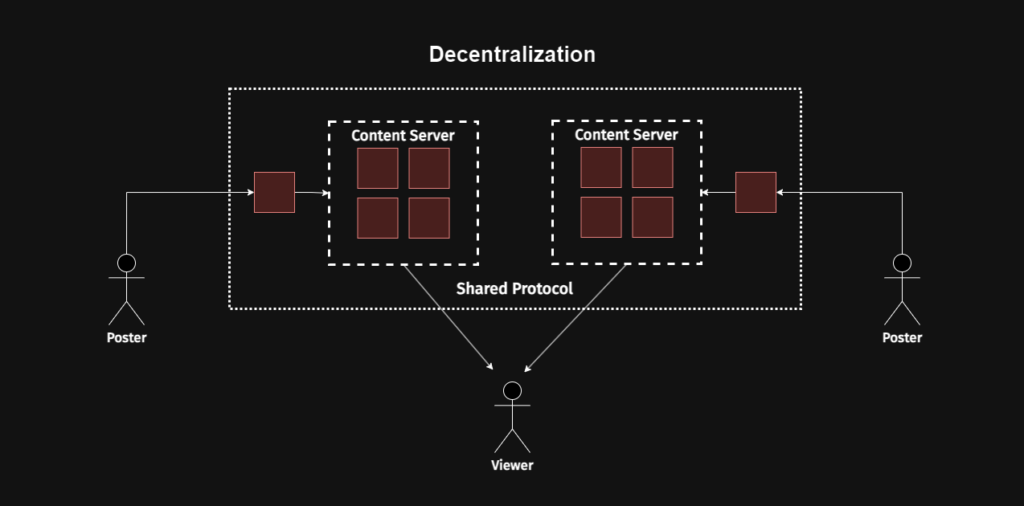
So yeah, Bluesky is attempting to take what is today a dominated landscape full of central platforms that can control your content and instead build something that will enable users to control where data flows as well as enable more third party integrations and open-sourced social media tech. But don’t take it from me:
Social media is too important to be controlled by a few corporations. We’re building an open foundation for the social internet so that we can all shape its future.
https://bsky.social/about
I again have to mention that I know this is not new. Mastodon has (as previously mentioned in other posts) also tried to achieve this and has success with their decentralized protocol called Activity Protocol. While I recognize the similarities I must stress that this post is not going to address them here as it would just add confusion by doing so.
ATProto Fundamentals
First let’s take a look at some basics within the ATProto specification. There’s a lot of complexity behind the protocol, but if we break things down into the key parts we can better understand things. The things I think are relevant to mention are the following:
- Personal Data Servers
- Identities
- Repositories
- Lexicons and Records
- Relays
Personal Data Servers (PDS)
The personal data server is the core unit within the use of ATProto which maintains information around identities that are tracked and those identities’ content and interaction data. Put very simply, any information that would be shared or verified is stored on these servers and ATProto enables other entities (including other Personal Data Servers) to create or modify or fetch data on the server.
When I mention resources like repositories, identities, and records, it is the PDS that usually manages and stores all of those. The storage specifics of whether data is stored in a database, or just as files, doesn’t matter. That is an implementation detail ATProto does not concern itself with.

Identities
Identities, A.K.A. users, actually use a standard that was created before ATProto which is very nice. The standard is called the Decentralized Identifier (DID) and actually has some nice docs over at W3C (link). Since you probably don’t want to read the actual docs, here are the highlights of why this standard is useful for something like ATProto:
- Enables user identities to be created in a globally unique way regardless of where created
- Enables identity verification to be decoupled from the server that creates the entity
- Through cryptography!
When creating a DID, there are some steps to perform that involve setting up things like the cryptographic key pairs, and some metadata about the user. The full specification of creating users also comes with methods for verification and this was all implemented under the name did:plc (plc is short for placeholder apparently and, like all placeholders in programming, became permanent). Now, if we think about the vision here, you may not use Bluesky’s servers to create identities. You can imagine it might be useful to have some way of knowing what server an identity calls home and what its public key is in a massive decentralized network of servers and content.
[ENTER] the global registry of user identities called the PLC directory!
Yes! The PLC directory! This is a massive registry that is currently maintaining public information about every identity Bluesky created. For example, here is my info:
# https://plc.directory/did:plc:a3npixnpiozqt5dnptmuqxzt/
{
"@context": [
"https://www.w3.org/ns/did/v1",
"https://w3id.org/security/multikey/v1",
"https://w3id.org/security/suites/secp256k1-2019/v1"
],
"id": "did:plc:a3npixnpiozqt5dnptmuqxzt",
"alsoKnownAs": ["at://birdhalfbaked.com"],
"verificationMethod": [{
"id": "did:plc:a3npixnpiozqt5dnptmuqxzt#atproto",
"type": "Multikey",
"controller": "did:plc:a3npixnpiozqt5dnptmuqxzt",
"publicKeyMultibase": "zQ3shwbqf2kgshnuAJwrtEeFy4PtVcFN8fT9nQXmydsJ6KDDp"
}],
"service": [{
"id": "#atproto_pds",
"type": "AtprotoPersonalDataServer",
"serviceEndpoint": "https://chanterelle.us-west.host.bsky.network"
}]
}Now this might seem weird to many, but I promise, with all my integrity, this is basically how we did PGP key registries for source contribution back in the day. Okay, so there’s more info being maintained, but still it is very common to define registries that are core in many decentralized verification protocols, so for me this at least rings familiar.
Repositories
On a personal data server, as mentioned you may have identities. Plural. This means you need a way to identify the content one identity produces from the content others produce. To facilitate this, ATProto introduces the concept of repositories. This is very similar to code repositories. So similar in fact that it, too, is implemented as a Merkle tree. If you are unfamiliar, a Merkle tree (or hash tree if you’re proper), it’s a tree structure where, for every linked data node, there is a calculated checksum attached that is the hash of its child nodes’ checksums.
checksumParent = Hash(checksumchild1 + checksumchild2 + ... + checksumchildN)
This allows fast verification of subparts of the tree. I.e. it lets you verify changes super efficiently which is ideal in large decentralized networks where synchronization of data can be prone to both error or bottlenecks. Since you know what parts would be missing based on the checksums, you can easily grab only the missing pieces. So essentially the idea here is by representing your content in these repositories like this, you enable your data to be reliably, securely, and efficiently synced between servers.
B-b-b-bonus info: since in a social media app you will have TONS of potential content updates (like added comments, or edits.) you do want to have some way of efficiently appending changes. Well, for the typical Merkle trees such operations can be problematic at times since they are usually not balanced nor guarantee key order in the naive forms (meaning appending data can be skewed in performance vs random updates), but this is why the creators of ATProto decided to pull from research and use a special type of Merkle tree called a Merkle Search Tree (MST). This is detailed in their referenced paper, but the key part here is that MSTs guarantee changes are appended to their respected content branch efficiently among an ordered key set (i.e. if keys are related to timestamps, you can search efficiently by chronological order; this is valuable in microblogging apps).
So yeah, Repositories are Merkle Trees! Neat.
Lexicons and Records
So we have repositories, and of course we are gonna have to store something there, and that’s where the specification for records come in. However, in ATProto a record is just a piece of JSON data, and since this can be anything, we need to know how to interpret what we might find in that data.
This is where lexicons come in. Lexicons describe a set of API functions as well as the schema that is expected when interacting with those functions. It so happens that the schemas defined in the lexicon are what map to the structure of the JSON records in a repository. Lexicons look very similar to a JSONSchema document, but with fields specific to ATProto. It doesn’t make sense to go into too much detail here as this would quickly just mirror what the ATProto documentation lists very succinctly. If you are interested in more details, though, I recommended instead reading some of the lexicons for Bluesky which are completely open source and available at: https://github.com/bluesky-social/atproto/tree/main/lexicons. Ultimately there is nothing fancy happening here but it helps to see examples.
Relays
On larger networks you may have many Personal Data Servers. A big problem, among other things, is that you need to manage discovery of servers and repositories. It doesn’t make a whole lot of sense to try and have clients be solely responsible for this, and it doesn’t either make sense to go the other extreme and make each personal data service responsible for relaying data or locations of other servers because this puts undue overhead on owning one, and remember the vision! We want things to be easy for server owners to encourage decentralization!
So, there is a spec for relays for those that have the ability to do relaying and build a consolidated stream of content for participants of the ATProto network. This stream of content that is unified is called the Firehose. Fancy name, but really it’s nothing we haven’t seen before. It is however convenient that these exist because you don’t want to have to keep scanning what could potentially be hundreds of servers even if discovery was taken care of.
With all that said, I think we can take a look at how ATProto glues these concepts together!
The Mechanics
When looking at protocols there are always at least three parts to look at when reviewing them:
- The data
- The operations
- The participants
The data
When it comes to transferring and storing bits, Bluesky themselves in the ATProto documentation admit they took a LOT of inspiration from the Interplanetary Linked Data codecs to build the data structures used, specifically the DAG-CBOR codec. It has the acronym DAG, because all objects can be linked as directed-acyclic graphs (they connect to each other so traversal happens in specific directions from one node to the next, no loops) and CBOR, which is a serialization standard sorta like JSON. The core need with CBOR is ultimate extensibility into the future and byte-determinism, which is an unnecessarily fancy way of saying when you serialize data, the same input always gives the same bytes. CBOR apparently is so extensible they even just allow raw binary with special tags just in case. If I am being honest, this is pretty overkill but hey, let them cook as the kids say.
Now, DAG-CBOR is great and all, but you need to package all this structure so that you can read the whole thing easily. To address that pain, there is a higher-level data format for this called Content Addressable aRchives (CAR). This is basically an envelope for all the DAG-CBOR content (similar to other archives that package multiple files into one flatter file). I want to wrap up this quick overview of how data looks when transmitted with an example of decoded DAG-CBOR content from my repo (truncated of course):
[{
"$type": "app.bsky.feed.like",
"createdAt": "2024-10-18T13:07:31.431Z",
"subject": {
"cid": "bafyreifddcgrjk7sgzdcd6dncclb6vdumvqg6mxk7qms5l4k2n5f7u4mji",
"uri": "at://did:plc:eixpzwwovy3m2juygpzta5he/app.bsky.feed.post/3l6odlaps6i2q"
}
}, {
"$type": "app.bsky.feed.post",
"createdAt": "2024-10-18T13:06:58.628Z",
"embed": {
"$type": "app.bsky.embed.images",
"images": [{
"alt": "",
"aspectRatio": {
"height": 2000,
"width": 1707
},
"image": {
"$type": "blob",
"mimeType": "image/jpeg",
"ref": "AVUSIH2763bYE2Er/jesWn0Kgs1/5sAmr/ad3wfhg9SVQ8qn",
"size": 859520
}
}]
},
"langs": ["en"],
"text": "I love seeing railways juxtaposed with nature. Something quaint and inspiring about the mix!"
}]A lot going on there, but the gist is that you can essentially think of this as containing the same structure more or less as JSON objects. Now what it looks like in terms of the actual bits differs quite a bit, but we don’t need to worry about that and several libraries (search for “CBOR Serialization library” in your favorite language) implement that part for you.
The operations
Looking at the supported operations is actually the easiest part of this protocol because they have basically kept things extremely simple and broke things down into two ways to interact via the protocol that allow for basically any operation to occur: batch RPC and streaming.
Batch RPC is performed via HTTP and this is nice because a lot of things are basically boiled down into REST-like semantics. They call this xRPC but this is confusing because there’s already an RPC system called xRPC and it’s not this. Basically this is just HTTP requests. Why did they call this xRPC? no one knows. I mean probably they know. I think. Anyway the whole point of xRPC is that the namespaced RPC calls can be anything and they need to support that. So theoretically I can just make my own xRPC endpoints which would then be handled by whatever service implements them.
Examples for a server could be:
POST /xrpc/birdhalfbaked.programSomethingPOST /xrpc/birdhalfbaked.makeCoffee
Some real examples from Bluesky that are probably more helpful:
POST com.atproto.repo.createRecordGET app.bsky.feed.getTimeline

Streaming is performed via websockets, and seems to be more of a way to subscribe to content streams rather than adding content. At least it is worded this way and so far only reading of subscribed topics over websocket is implemented. It seems to support backfilling (meaning getting messages previous to the current live messages coming in), though it seems that the limits to this are also dependent on individual implementation. So yeah, you can get a stream of updates over websocket and that’s about it.
And just a quick callback reminder that ultimately both of these types of APIs form the lexicons we mentioned earlier in the ATProto Fundamentals section. And lexicons come with both the operations and the data schemas for those operations.
The participants
As with any protocol, something needs to use it. Pretty much all operations are done as an authenticated user, but that’s not necessarily the only participant. So here are the participants we can have in any use of this protocol:
- Users – Content creators and primary initiators of actions in the network via the protocol. I.e. you!
- Personal Data Servers – The primary responders or content providers. Personal data servers are also responsible for implementing the authentication controls.
- Applications – Backend Programs or frontend clients that sits in the middle between users and personal data servers to facilitate operations and manage states that the protocol is unaware of. Applications can also act on behalf of users when authorized to do so via OAuth.
In Bluesky, the servers maintain an identity for you guarded behind user/pass authentication on the app. This means that when a user wishes to post content to the Bluesky servers and registers, Bluesky is also doing the behind-the-scenes setup to take care of the identity creation for you as well. The ATProto spec doesn’t require this to be how this happens outright, but keeps this as a simple way of enabling users to create an identity since it’s much easier to hide the cryptographic details from users that are not super technical.

There is the open possibility to fully decentralize user identity since regardless of the servers maintaining your identity, verification of your content and actions as represented in your repositories is through cryptographic means. In fact, they are leaning into the Decentralized ID (DID) W3C standards (reference) in order to implement things, so yeah, even though Bluesky is federated this again is not a hard requirement and there is no reason you couldn’t create your own identity and then create your own content on your own server while you maintain your own cryptographic keys and sign content yourself before sending it to the server you maintain.
While not explicitly required by ATProto, it should be mentioned that since Personal Data Servers that manage multiple users cannot just blindly trust requests; there needs to be an authorization mechanism and that does mean you do need to provide this on the server. Bluesky, believe it or not, did not reinvent the wheel here, and instead used user/password flows that generate JSON Web Tokens for their app and they use OAuth for third party integrations. The ATProto spec mentions some required details around use of OAuth but to be honest it’s not fully fleshed out yet in my humble opinion. I’ll get to some of that later as we explore.
The current Bluesky servers, according to the code in their repos, is using what ATProto docs calls “legacy” authorization of users which is just a typical JSON web token auth flow with refresh tokens managed by the server after user/password checking (here’s the sauce). To be honest though, there is no hard requirement on how PDSs take care of that since managing internal identities is left up to the implementors for the most part. Lot’s of SHOULDs and few MUSTs in that regard.
Let’s recap
So, ATProto uses CBOR to serialize data, and it links things together using directional graphs called a DAGs. Combine this and you get DAG-CBOR. This data is then managed via operations over batch and streaming endpoints that PDS servers implement and clients consume. Interactions between all of this happens within authorized contexts that are managed (usually) by leveraging OAuth.
Exploring the SDKs
Okay, so we’re done with the boring stuff, and now is the time I want to play around. It’s important to get some practical work with some of the protocol because in practice a lot of this stuff only makes sense when you play around and actually experiment. Note: in this post I will not be exploring the Firehose (websocket) streaming as that is more intended for server-server syncing and feed generators etc. My goal is to just give you enough inspiration to be dangerous!

Now, Bluesky has two official client SDKs and one unofficial-but-endorsed client SDK for Python.
- Official
- Unofficial
Since only the Typescript library is fully-featured according to their own documentation, that’s what I will use. Since I also don’t really want to mess with the environments I have locally, etc. etc. I’ll just be dockerizing this to make this an enjoyable experience for myself. Now I admit I am not someone that really uses TS/JS for their career, I know about it, but I am sure that I can manage to get some reasonably clean examples here, but just in case here is the repo so that you can show me how to actually code in Typescript:

Authenticating against Bluesky’s PDSs
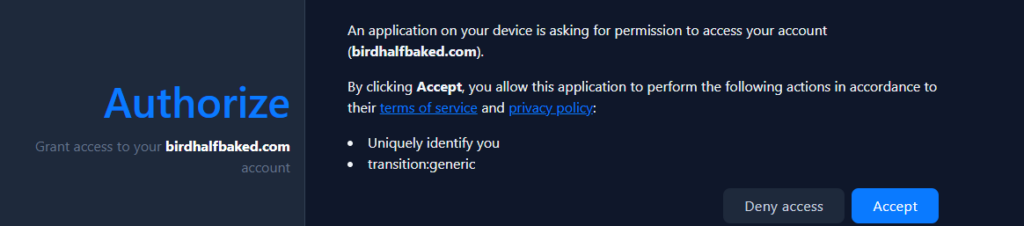
This is of course the first point right? Starting out by connecting to a Bluesky server and getting acknowledgement. Now since technically the user-pass based auth is deprecated I should say at this point we will need to use the OAuth2.0 flow to keep compliant with the modern version of the Protocol and implementation.

Basically, my simple idea is/was to create a server where some routes trigger API calls using an authenticated agent I create via OAuth flows. To do this I create a server using something I found people use called Express.js. I then use the @atproto/oauth-client-node library to setup an OAuth client that creates some agent that is usable for authenticated API calls. This only requires that I set up a redirection path, and implement some of the mandatory state stores that the node.js OAuth client needs so it was the easiest path for me. Again I am not a typescript professional so I don’t know how good the code looks, only that it works using a combo of copy paste from ATproto docs and tweaks. That said, I did note some interesting things about ATProto’s use of OAuth…
ATProto OAuth caveats
So for the most common case in OAuth, you have a client ID and client secret that is generated by the service which you intend to authenticate your application against. Well in ATProto this is generalized so that you don’t need any single central maintainer of trusted IDs and secrets etc. If you have a way to generate keys and enable verification of identity through those this problem is solved, but of course you need to also accommodate what OAuth calls “public” clients as well. So ATProto says, let’s invent a client ID standard based on a host path! That is, I could use https://birdhalfbaked.com as the client ID. ATProto abuses OAuth’s lack of specification here and allows a lot more pathing to be used in the client ID than I care for. For example, I could declare scopes and redirect URIs as part of the client ID arbitrarily:
https://birdhalfbaked.com?scope=atproto transition:generic&redirect_uri=https://birdhalfbaked.com/atproto-oauth-callback&some_param_that_can_just_be_used_to_get_by_checks=1While the above is an invalid client ID, it depends on the server recognizing this and rejecting this. Furthermore, order doesn’t matter, so you can abuse that too. And also spaces are preserved in scope and ahhhhhhhhhhh. It’s a nightmare in my mind to think of the scenarios one could open the door to some cheeky shenanigans.
Anyway it’s what we have for now, and as long as servers are careful about their verification implementations it surely won’t result in anything bad. I hope. This is a key problem in decentralization by the way… a LOT of safeguards become the responsibility of the implementor and it can go wrong very easily.
The localhost special case
Since I don’t want to go into the weeds of creating signed certs for a local docker image, I will use the special case defined in the ATProto docs of having localhost specified as a client ID. This enables developers to specify non-secure redirect URLs. Again I can’t stress this enough that this is not something the protocol can guarantee, and it can be implemented wrong in other servers that ignore that check, so be careful!
In the end if you want a copy-paste version of this to play around with, you can reference how I set things up in my oauth.ts client file: https://github.com/birdhalfbaked/explore-atproto/blob/main/client/src/oauth.ts
Okay let’s explore!
So now that I covered that we setup authentication via OAuth (I ain’t no user-pass cheater!), the remaining thing was to have some routes that use our fancy authenticated agent from the OAuth flow to do some actual work :D. I didn’t think it would be practical to check ALL of the allowed actions, so I only picked a few from various subsystems within Bluesky. Here are the routes I decided to make in my little application. I know it isn’t super organized on the routes side, but here is what we got:
- Profile and social info
- Get my profile details
GET /profile
- List who I follow
GET /followers
- Get my profile details
- Feeds and content
- Read my 5 latest posts
GET /myPosts
- Read my timeline’s 5 latest posts
GET /posts
- Create a test post
POST /createTest
- Read my 5 latest posts
- Custom XRPC calls
- Top 5 globally popular feed generators
GET /feeds
- Open the gates!
GET /xrpc/:method
- Top 5 globally popular feed generators
Inspecting all the responses
Since this is all just the result of web responses, it is easy to just dump this one by one (until the XRPC route ;)). So how’d we do?
Profile and social info:
# /profile
{"name":"Birdy@birdhalfbaked.com","did":"did:plc:a3npixnpiozqt5dnptmuqxzt","followers":11,"following":13}
# /profile/followers
[
"Alexis@alexisbouchez.bsky.social",
"Sleepyhead Games@sleepyheaddevs.bsky.social",
...
]Feeds and content
# /posts - only one example shown
[
{
"author":"@babachoo.bsky.social",
"createdAt": "2024-11-03T11:13:04.198Z",
"likes":1,
"reposts":0,
"replies":0,
"content":"=O now THAT'S some perfect Steam Capsule art if I ever did see it, lol. Amazing."
},
...
],
# /posts/me - only one example shown
[
{
"createdAt":"2024-11-02T23:55:27.663Z",
"likes":0,
"reposts":0,
"replies":0,
"content":"Cool reminder that the way ATProto repositories are indexed are in Merkle Search Tree structures which were formalized in 2019 inria.hal.science/hal-02303490.... Practical tech research at it's finest"
},
...
]Custom XRPC calls
Now here’s the interesting stuff. Interesting because this is not typically exposed through the public API methods of the clients, but remember from before that basically all lexicon actions are just XRPC calls. So there are some ways we can get around the fact there is no bespoke method.
The trick lies within this line of code:
let response = await agent.app._client.call(nsid: string, params?: object)Basically this will trigger a proper XRPC call even though there is not a public method. The call method will also accept params, so for getting the list of the globally-popular feeds for instance we can just do the following:
let response = await agent.app._client.call("app.bsky.unspecced.getPopularFeedGenerators", { limit: 5 });
let feeds = response.data.feeds.map(feed => {
return {
"name": feed.displayName,
"description": feed.description,
"likes": feed.likeCount
}
})Notice I can still pass in the limit as a param. Now how did I know that this limit was a parameter that could be used? It’s all in the lexicon!
# lexicon spec at https://github.com/bluesky-social/atproto/blob/main/lexicons/app/bsky/unspecced/getPopularFeedGenerators.json
...
"parameters": {
"type": "params",
"properties": {
"limit": {
"type": "integer",
"minimum": 1,
"maximum": 100,
"default": 50
},
"cursor": { "type": "string" },
"query": { "type": "string" }
}
},
...That’s also how I knew what properties were available on the response. However, there is no better way to explore than to just play around, so feel free to use the same code and just call your own nsid commands to see what you can do! I added a special route for just that so you can call whatever XRPC method you want.
Example:
# describe the ATProto PDS server
http://127.0.0.1:8080/xrpc/com.atproto.server.describeServer
# if you want to add params, no problem
http://127.0.0.1:8080/xrpc/com.atproto.repo.describeRepo?repo=birdhalfbaked.comI think I will leave it as is here. This has been an absolute blast to be able to play with actual routes. Again, should you want to play around a bit, please please please feel free to clone the code and set it up yourself. The Readme should contain all the steps to get you going against Bluesky’s servers.
GO OUT AND BUILD >:D
What’s next
With this all being explored and dived into, this wraps up a somewhat-lengthy dig into ATProto. I think ending on a practical note of getting a small application to read information and interact with the Bluesky servers is fantastic. However, I alluded to a third part coming up that is even more fun:
Making a Personal Data Server!
Yes, this is where we are heading; deploying our own content server which should in theory work with Bluesky the app! I will be using some of the code available from the creators, but I also want to explore some of the unimplemented parts. Things like private repositories have been hitting a lot of users’ wishlists and it is theoretically possible to do a LOT of things with the protocol as it is today so I want to explore what implementations of that look like. So that’s where I will be putting effort next! I hope it’s also not too lengthy, but to be fair it was important to cover enough detail of ATProto to build the foundation of the next steps, so until then, see you when we create our own PDS and deploy it!
PS: this also means next time we will get to stream some data from Firehose 😉